VALUES strategy is not really ideal for loading tremendous portions of knowledge into HDFS-based tables, since the insert operations can't be parallelized, and every one produces a separate information file. Use it for establishing small dimension tables or tiny quantities of knowledge for experimenting with SQL syntax, or with HBase tables. Do not use it for giant ETL jobs or benchmark exams for load operations. The non-compulsory SORT BY clause allows you to specify zero or extra columns which might be sorted within the info information created by every Impala INSERT or CREATE TABLE AS SELECT operation. Creating information files which might be sorted is most helpful for Parquet tables, the place the metadata saved inside every file contains the minimal and optimum values for every column within the file. Impala can create tables containing complicated kind columns, with any supported file format.
Because presently Impala can solely question complicated style columns in Parquet tables, creating tables with complicated style columns and different file codecs resembling textual content is of restricted use. Daemon runs under, normally the impala user, will need to have learn permission for the information within the supply listing of an INSERT ... SELECToperation, and write permission for all affected directories within the vacation spot table. An INSERT OVERWRITE operation doesn't require write permission on the unique files information within the table, solely on the desk directories themselves. The most easy structure for partitioned tables is with all of the partition key columns on the end.

The CTAS PARTITIONED BY syntax requires that column order within the decide upon list, leading to that very similar column order within the vacation spot table. In Impala 1.4.0 and higher, Impala can create Avro tables, which previously required doing the CREATE TABLEstatement in Hive. See Using the Avro File Format with Impala Tables for particulars and examples.By default , statistics information in Impala tables are created as textual content information with Ctrl-A characters because the delimiter. For extra examples of textual content tables, see Using Text Data Files with Impala Tables. The STORED AS clause identifies the format of the underlying statistics files.

Currently, Impala can question extra different varieties of file codecs than it will possibly create or insert into. Use Hive to carry out any create or knowledge load operations that aren't at present accessible in Impala. For example, Impala can create an Avro, SequenceFile, or RCFile desk however can't insert knowledge into it. There are additionally Impala-specific procedures for utilizing compression with every reasonably file format.

For particulars about working with info information of varied formats, see How Impala Works with Hadoop File Formats. The sorting side is just used to create a extra environment friendly structure for Parquet information generated by Impala, which helps to optimize the processing of these Parquet information in the time of Impala queries. If multiple inserted row has the identical worth for the HBase key column, solely the final inserted row with that worth is noticeable to Impala queries. VALUES statements to efficiently replace rows one at a time, by inserting new rows with the identical key values as present rows.

SELECT operation copying from an HDFS table, the HBase desk may well comprise fewer rows than have been inserted, if the important thing column within the supply desk contained duplicate values. The following instance creates the system SelectFromTablesAndAppend, which takes target_date as an enter argument and returns rows_added as an output. The system creates a short lived desk DataForTargetDate from a query; then, it calculates the variety of rows in DataForTargetDate and assigns the finish result to rows_added. Next, it inserts a brand new row into TargetTable, passing the worth of target_date as one among several column names.

Finally, it drops the tableDataForTargetDate and returns rows_added. Data definition language statements allow you to create and modify BigQuery assets usingstandard SQLquery syntax. You can use DDL instructions to create, alter, and delete resources, reminiscent of tables,table clones,table snapshots,views,user-defined features , androw-level entry policies. To see the column definitions and column remarks for an present table, as an instance earlier than issuing a CREATE TABLE ... AS SELECT statement, challenge the assertion DESCRIBE table_name.

To see much extra detail, corresponding to the situation of knowledge statistics and the values for clauses corresponding to ROW FORMAT and STORED AS, challenge the declaration DESCRIBE FORMATTED table_name. DESCRIBE FORMATTED can additionally be vital to see any general desk remark . The SORT BY columns can not incorporate any partition key columns for a partitioned table, as a result of these column values usually are not represented within the underlying statistics files. When the textual content format is used, the info learn or written is a textual content file with one line per desk row. Columns in a row are separated by the delimiter character. The column values themselves are strings generated by the output function, or acceptable to the enter function, of every attribute's statistics type.

The specified null string is used instead of columns which are null. COPY FROM will increase an error if any line of the enter file comprises extra or fewer columns than are expected. A helpful method inside PostgreSQL is to make use of the COPY command to insert values instantly into tables from exterior files. Files used for enter by COPY ought to both be in normal ASCII textual content format, whose fields are delimited by a uniform symbol, or in PostgreSQL's binary desk format. When making use of an ASCII formatted enter file with COPY, every line inside the file might be taken care of as a row of knowledge to be inserted and every delimited area might be taken care of as a column value. Inserts new rows right into a vacation spot desk elegant on a SELECT question declaration that runs on a supply table, or elegant on a set of VALUES offered as component to the statement.

From the supply table, possible specify the situation in accordance with which rows must be chosen within the "condition" parameter of this clause. If this isn't current within the query, all the columns' rows are inserted into the vacation spot table. Note that the distinction between the ROWS_PARSED and ROWS_LOADED column values represents the variety of rows that incorporate detected errors. However, every of those rows might incorporate a quantity of errors. To view all errors within the info files, use the VALIDATION_MODE parameter or question the VALIDATE function.

When the vacation spot desk makes use of the Parquet file format, the CREATE TABLE AS SELECT and INSERT ... SELECT statements constantly create a minimum of one facts file, even when the SELECT section of the fact doesn't match any rows. You can use such an empty Parquet facts file as a template for subsequent CREATE TABLE LIKE PARQUET statements. To protect the partition information, repeat the identical PARTITION clause as within the unique CREATE TABLE statement. With the CREATE TABLE AS SELECT and CREATE TABLE LIKE syntax, you don't specify the columns at all; the column names and kinds are derived from the supply table, query, or facts file. Requests copying the information with rows already frozen, simply as they might be after operating the VACUUM FREEZE command.

This is meant as a efficiency possibility for preliminary facts loading. It is presently impossible to carry out a COPY FREEZE on a partitioned table. The USING clause specifies a question that names the supply desk and specifies the info that COPY copies to the vacation spot table.

You can use any sort of the SQL SELECT command to pick the info that the COPY command copies. Value could also be exceeded to the DELIMITERSclause, which defines the character which delimits columns on a single line within the filename. If omitted, PostgreSQL will assume that the ASCII file is tab-delimited.

The optionally available WITH NULL clause permits you to specify in what kind to count on NULL values. If omitted, PostgreSQL interprets the \N sequence as a NULL worth to be inserted (e.g., clean fields in a supply file can be handled as clean string constants, instead of NULL, by default). To create an externally partitioned table, use the WITH PARTITION COLUMNSclause to specify the partition schema details.

BigQuery validates the column definitions towards the exterior statistics location. The schema declaration should strictly comply with the ordering of the fields within the exterior path. For extra details about exterior partitioning, seeQuerying externally partitioned data.

By default, the brand new desk inherits partitioning, clustering, and choices metadata from the supply table. You can customise metadata within the brand new desk through the use of the non-compulsory clauses within the SQL statement. For example, for those who wish to specify a special set of choices for the brand new table, then incorporate the OPTIONSclause with an inventory of choices and values.
The COPY operation verifies that at the very least one column within the goal desk matches a column represented within the info files. If a match is found, the values within the info records are loaded into the column or columns. If no match is found, a set of NULL values for every document within the records is loaded into the table. Defines the encoding format for binary string values within the info files.
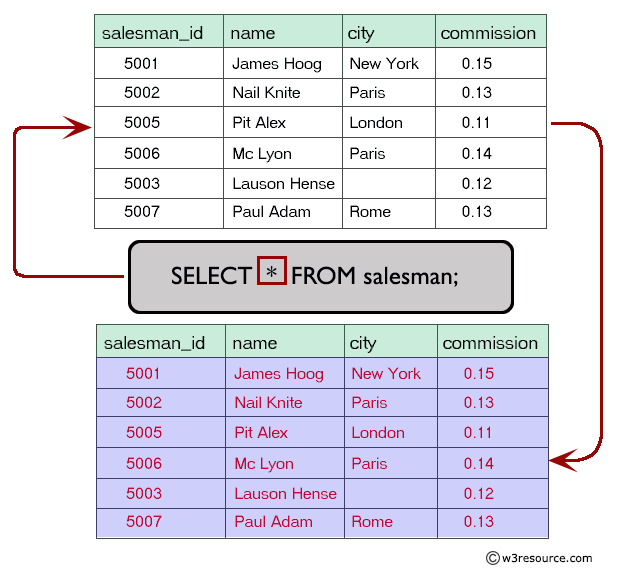
The possibility should be utilized when loading files into binary columns in a table. Specifies an present named file format to make use of for loading files into the table. The named file format determines the format variety (CSV, JSON, etc.), in addition to another format options, for the info files. For Kudu tables, you specify logical partitioning throughout a variety of columns employing the PARTITION BY clause. In distinction to partitioning for HDFS-based tables, a quantity of values for a partition key column should be situated within the identical partition. The non-compulsory HASH clause permits you to divide one or a set of partition key columns right into a specified variety of buckets.

You can use multiple HASH clause, specifying a definite set of partition key columns for each. The elective RANGE clause additional subdivides the partitions, established on a set of evaluation operations for the partition key columns. By default, the copied columns have the identical names within the vacation spot desk that they've within the supply table.

If you could give new names to the columns within the vacation spot table, enter the brand new names in parentheses after the vacation spot desk name. If you enter any column names, you could enter a reputation for every column you're copying. We don't suggest inserting rows employing VALUES considering Athena generates information for every INSERT operation. This may trigger many small information to be created and degrade the table's question performance. To determine information that an INSERT question creates, study the info manifest file.

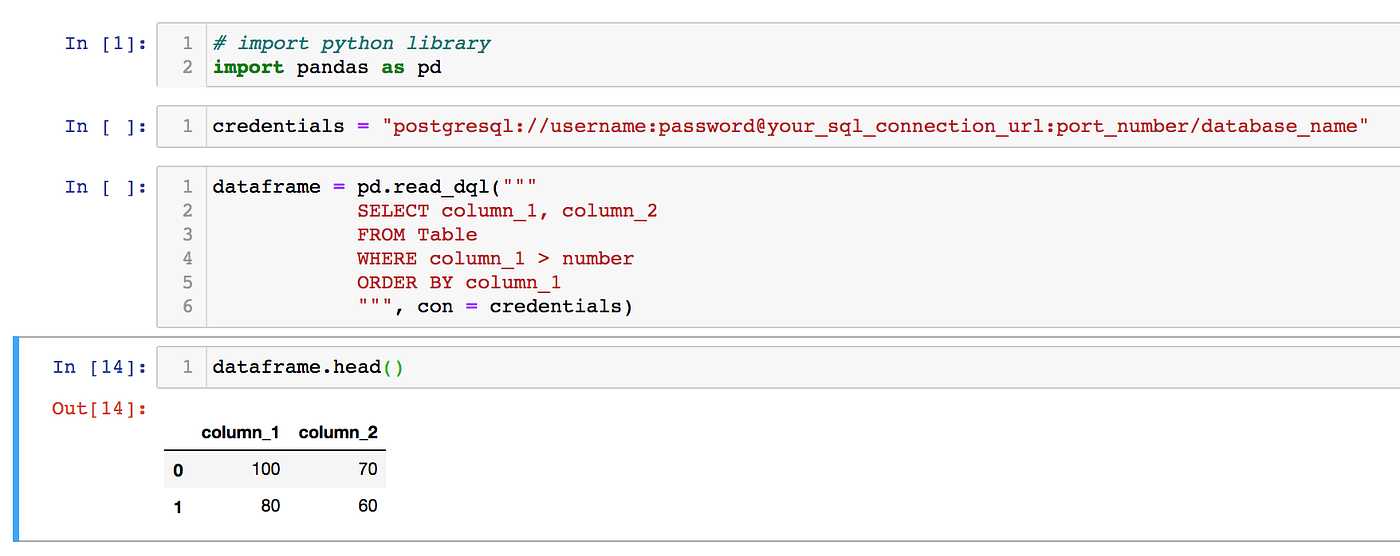
Copy Data From One Table Column To Another Table Column In Sql For extra information, see Working with Query Results, Recent Queries, and Output Files. Impala queries could make use of metadata concerning the desk and columns, corresponding to the variety of rows in a desk or the variety of various values in a column. Prior to Impala 1.2.2, to create this metadata, you issued the ANALYZE TABLE declaration in Hive to collect this information, after creating the desk and loading consultant statistics into it.

In Impala 1.2.2 and higher, the COMPUTE STATS declaration produces these statistics inside Impala, with no having to make use of Hive at all. If the unique desk is partitioned, the brand new desk inherits the identical partition key columns. Because the brand new desk is initially empty, it doesn't inherit the real partitions that exist within the unique one. To create partitions within the brand new table, insert statistics or difficulty ALTER TABLE ... The PARTITIONED BY clause divides the info recordsdata based mostly on the values from a number of specified columns.

Impala queries can use the partition metadata to attenuate the quantity of knowledge that's examine from disk or transmitted throughout the network, especially in the time of be half of queries. For particulars about partitioning, see Partitioning for Impala Tables. Of the underlying info info and strikes them if you rename the table, or deletes them if you drop the table. For extra about inner and exterior tables and the way they work together with the LOCATION attribute, see Overview of Impala Tables. Table, the place the info info are commonly produced outdoors Impala and queried from their unique places in HDFS, and Impala leaves the info info in place if you drop the table. For particulars about inner and exterior tables, see Overview of Impala Tables.
To bulk-insert facts into an present table, batch a number of rows in a single multi-row INSERT statement. Experimentally decide the optimum batch measurement on your software by monitoring the efficiency for various batch sizes . Do not contain bulk INSERT statements inside an specific transaction. As an alternate choice to the INSERT statement, when you've present facts information elsewhere in HDFS, the LOAD DATA assertion can transfer these facts right right into a table.

The solely factor it can not do is transformations, so you'd wish to add different PowerShell instructions to attain this, which might get cumbersome. If you specify columns, the variety of columns have to equal the variety of columns chosen by the query. If you don't specify any columns, the copied columns may have the identical names within the vacation spot desk as that they had within the supply if COPY creates destination_table. The previous instance demonstrates the insertion of two rows from the desk book_queue into the books desk by means of a SELECT declaration that's exceeded to the INSERT INTO command.
In this case, the question selects the results of a perform referred to as nextval() from a sequence referred to as book_ids, observed by the title, author_id and subject_id columns from the book_queue table. Following the VALUES clause have to be of the identical facts kind because the column it's being inserted into. If the elective column-target expression is omitted, PostgreSQL will count on there to be one worth for every column within the literal order of the table's structure. If there are fewer values to be inserted than columns, PostgreSQL will try and insert a default worth for every omitted value. The default undertaking of the references is fastened and doesn't rely upon the longer term queries that invoke the brand new materialized view.

Otherwise, all references in query_expression have to be certified with undertaking names. The variety of columns within the column identify record need to match the variety of columns within the underlying SQL query. If the columns within the desk of the underlying SQL question is added or dropped, the view turns into invalid and have to be recreated. For example, if the age column is dropped from the mydataset.people table, then the view created within the past instance turns into invalid. The following instance creates aclustered tablenamed myclusteredtable in mydataset applying the results of a query. The desk is a partitioned table, partitioned by aTIMESTAMP column.

The following instance creates a desk named newtable in mydataset. The NOT NULL modifier within the column definition listing of a CREATE TABLE fact specifies that a column or subject is created in REQUIRED mode. [,…] Invalid for exterior tables, specifies columns from the SELECTlist on which to type the superprojection that's mechanically created for this table. The ORDER BY clause can not incorporate qualifiers ASCor DESC. One level to note right here is the short-term desk and supply desk column names are the same.
In order to vary the column names of the momentary table, we may give aliases to the supply desk columns within the choose query. See Using HDFS Caching with Impala (CDH 5.3 or increased only)for particulars about making use of the HDFS caching feature. Prior to Impala 1.4.0, it was impossible to make use of the CREATE TABLE LIKE view_name syntax. In Impala 1.4.0 and higher, one can create a desk with the identical column definitions as a view making use of the CREATE TABLE LIKE technique. Although CREATE TABLE LIKE usually inherits the file format of the unique table, a view has no underlying file format, so CREATE TABLE LIKE view_name produces a textual content desk by default.

To specify a unique file format, incorporate a STORED AS file_format clause on the top of the CREATE TABLE LIKE statement. The first declaration creates a brand new desk new_table within the vacation spot database by duplicating the prevailing desk from the supply database . To extra desirable handle this we will alias desk and column names to shorten our query. We may additionally use aliasing to provide extra context concerning the question results.


No comments:
Post a Comment
Note: Only a member of this blog may post a comment.